rdma杂谈,这个写得太好了,可以先看知乎看一两节,再看tutorial,再看回来
很多都是我复制的
RDMA概述
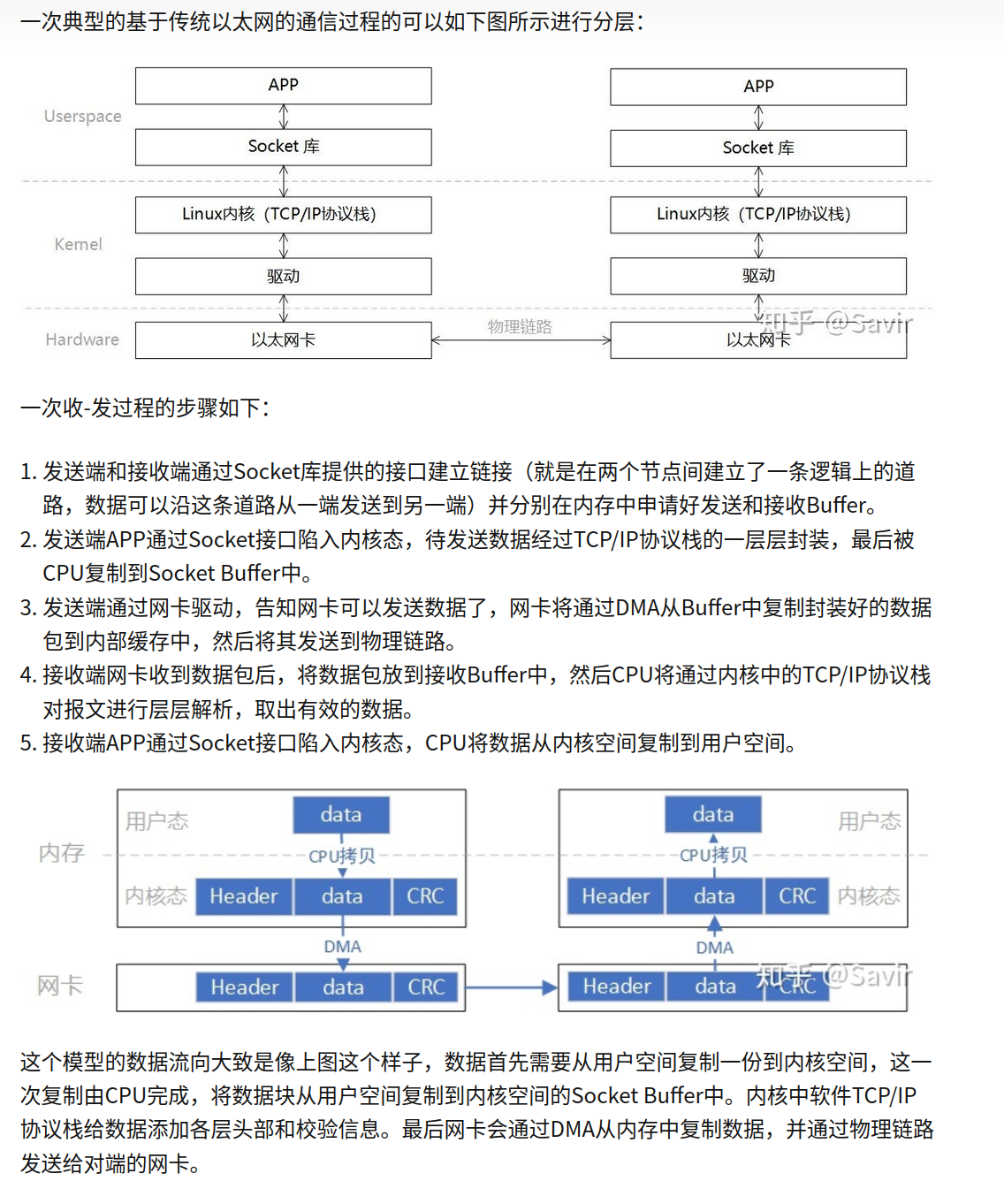
回忆一下组原有个dma,设备把数据直接发送到内存,不需要cpu参与
但是如果两台机器要发消息,就要通过传统网络栈,用户空间内存通过cpu拷贝到内核空间内存,内核空间内存dma到网卡,才能用网卡发送出去;接受的时候也是。
rdma:remote direct memory access
从一个主机的内存直接访问另一个主机的内存
将rdma协议固化到网卡上
优势:
- 零拷贝(不需要用户空间内核空间来回拷贝)
- 内核旁路
- 不需要cpu干预
- 消息基于事务(数据不是流而是离散的)
- 支持分散聚合条目
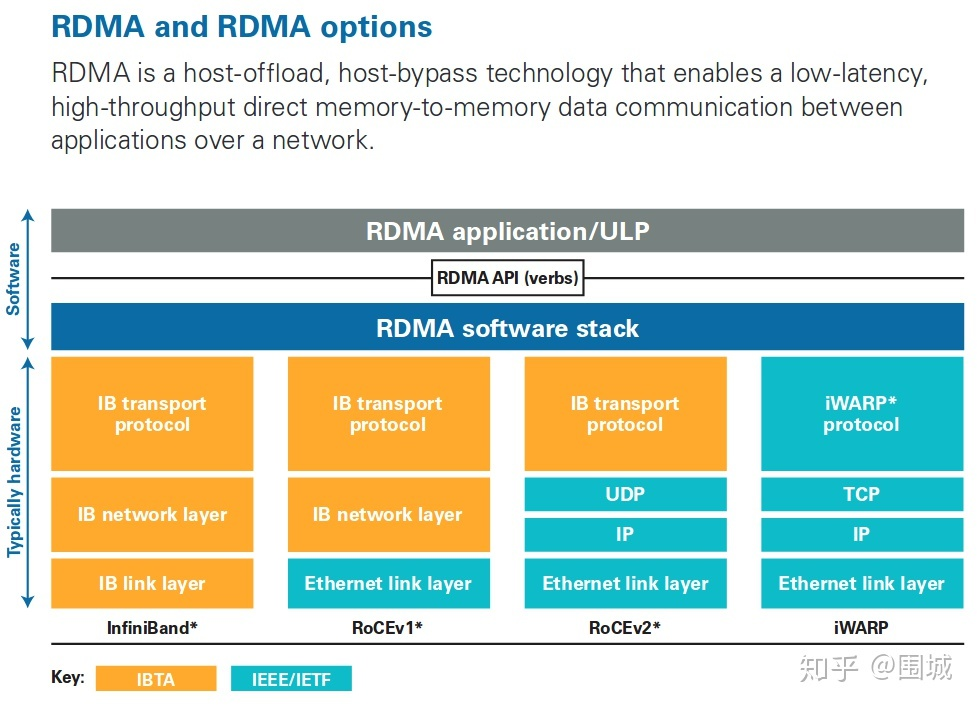
三种硬件实现
InfiniBand/IB,全新协议,全新交换机网卡
RDMA over Ethernet/ RoCE,普通以太网交换机,新网卡(pdsl用这一套)
- v1基于以太网交换机
- v2基于udp
iWARP/RDMA over TCP
比较基于传统以太网与RDMA技术的通信
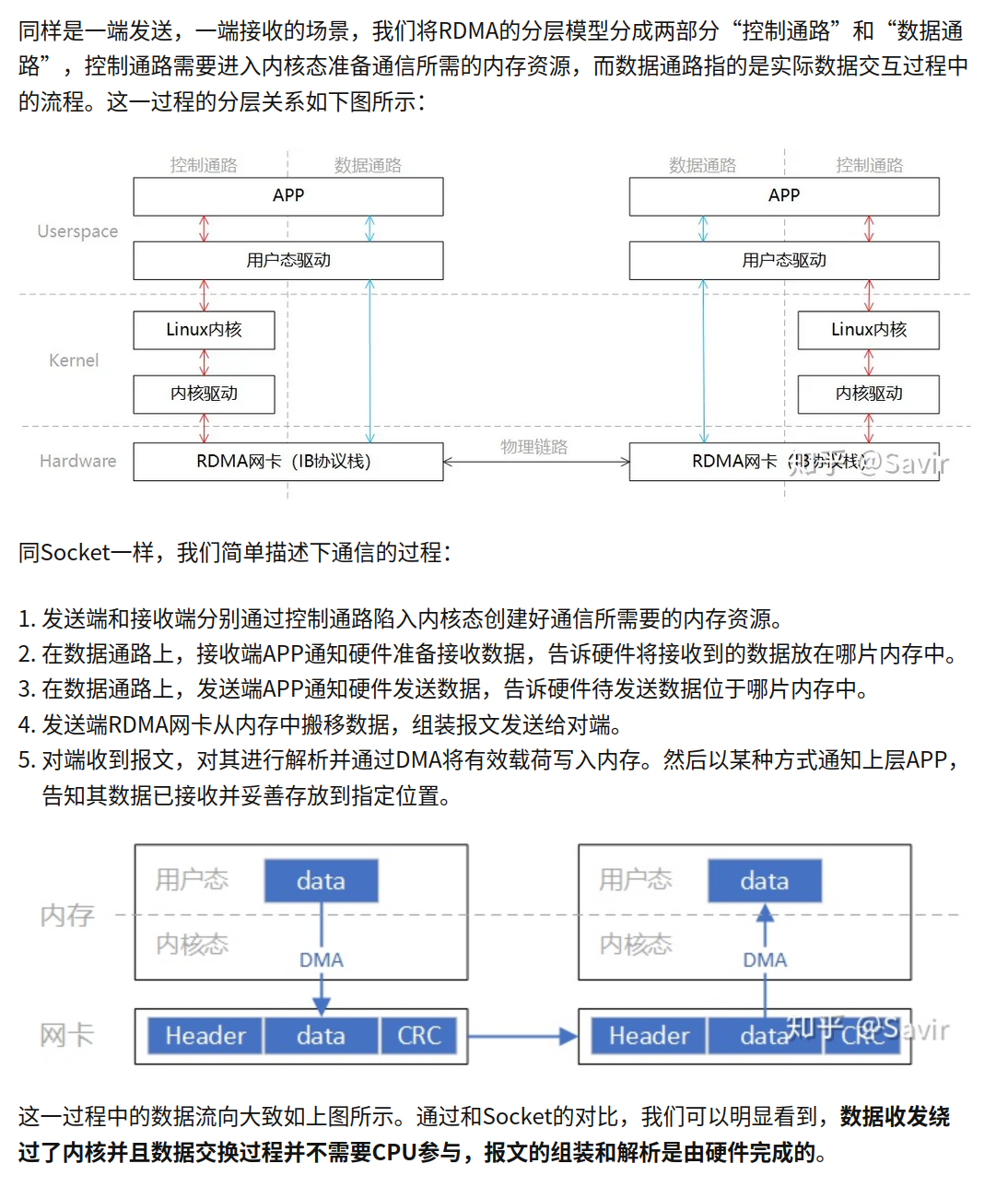
注意的重点:陷入内核态、网卡DMA拷贝
至于rdma,也不是完全离开了cpu和内核,控制还是需要一点的。
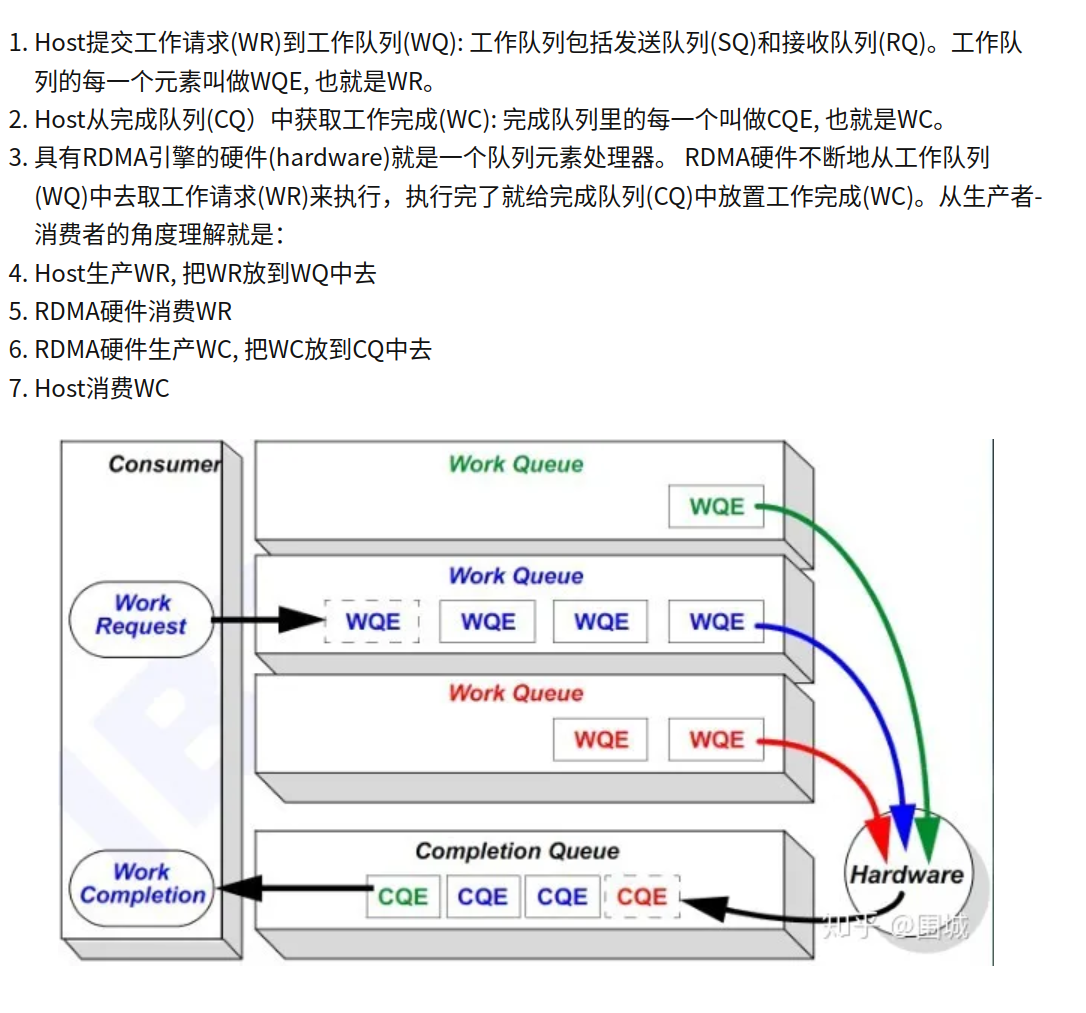
RDMA基本元素和缩写(待补充)
好好看,好好背
WQ work queue,其中的元素叫WQE work queue entry,可以理解为任务说明。这个是概念。它们的实例是SQ send queue, RQ receive queue
SQ和RQ组成QP queue pair,这才是通信的基本单位。QP有编号,称为QPN.一个进程可能有好几对qp
有SQR shared receive queue(不是s&r q),几个qp共享一个rq,因为使用rq的情况小
CQ completion queue,自然也有CQE。
WQ是软件push硬件pop,CQ是硬件push软件pop
WR是work request,WC是work completion,是WQE和CQE在用户层的映射,用户收发的也是它们。而wqe和cqe其实是驱动的概念。
后面提到的术语:
QPC queue pair context,qp上下文,标识着qp的连接信息
MR memory region(见第六节)
HCA host channel adapter 宿主通道适配器,可以理解为硬件部分
L_KEY(Local Key)和R_KEY(Remote Key),保障本端远端内存访问权限
PD protection domain PD像是一个容纳了各种资源(QP、MR等)的“容器”,将这些资源纳入自己的保护范围内,避免他们被未经授权的访问。
GID Global Identifier 全局id
AH Address Handle
cm communication management 建链用
RDMA操作类型
双端操作:一端进行send,另一端必须进行recv,收端要先下发wqe。
write:本端主动写入远端内存。除了准备阶段,远端cpu不参与
本端是通过虚拟地址读写远端内存的,而虚拟地址到物理地址转换是rdma网卡干的。
RDMA WRITE/READ才是大量传输数据时所应用的操作类型,SEND/RECV通常只是用来传输一些控制信息。
RDMA基本服务类型
就像tcpip有tcp udp一样,rdma也有以可靠/不可靠、连接/数据包区分的四种服务类型
可靠服务在发送和接受者之间保证了信息最多只会传递一次,并且能够保证其按照发送顺序完整的被接收
- 应答机制
- 校验机制
- 保序机制
对于基于连接的服务来说,每个QP都和另一个远端节点相关联。在这种情况下,QP Context中包含有远端节点的QP信息。在建立通信的过程中,两个节点会交换包括稍后用于通信的QP在内的对端信息
QPC 即QP context ,QP 上下文。
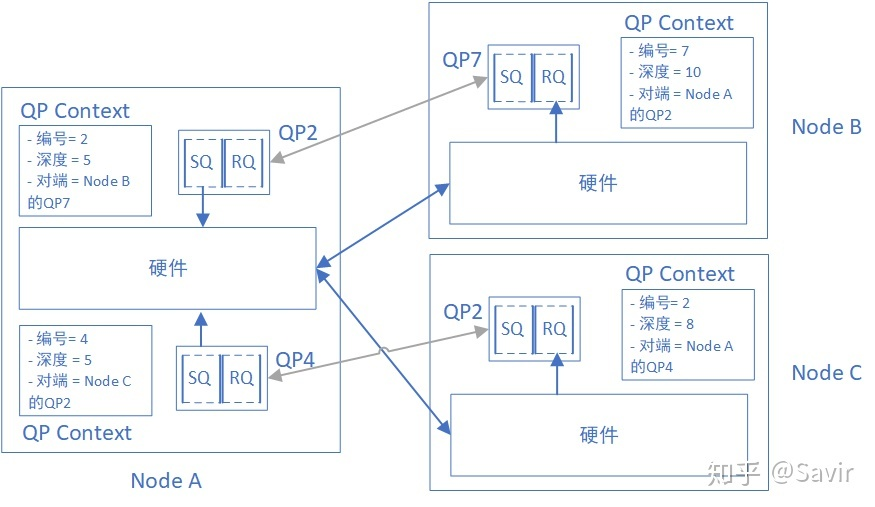
在连接服务类型中的每个QP,都和唯一的另一个QP建立了连接,也就是说QP下发的每个WQE的目的地都是唯一的。
对于数据包来说,不会保存远端节点

RC和UD使用最多,可以类比为tcp udp
RDMA之Memory Region
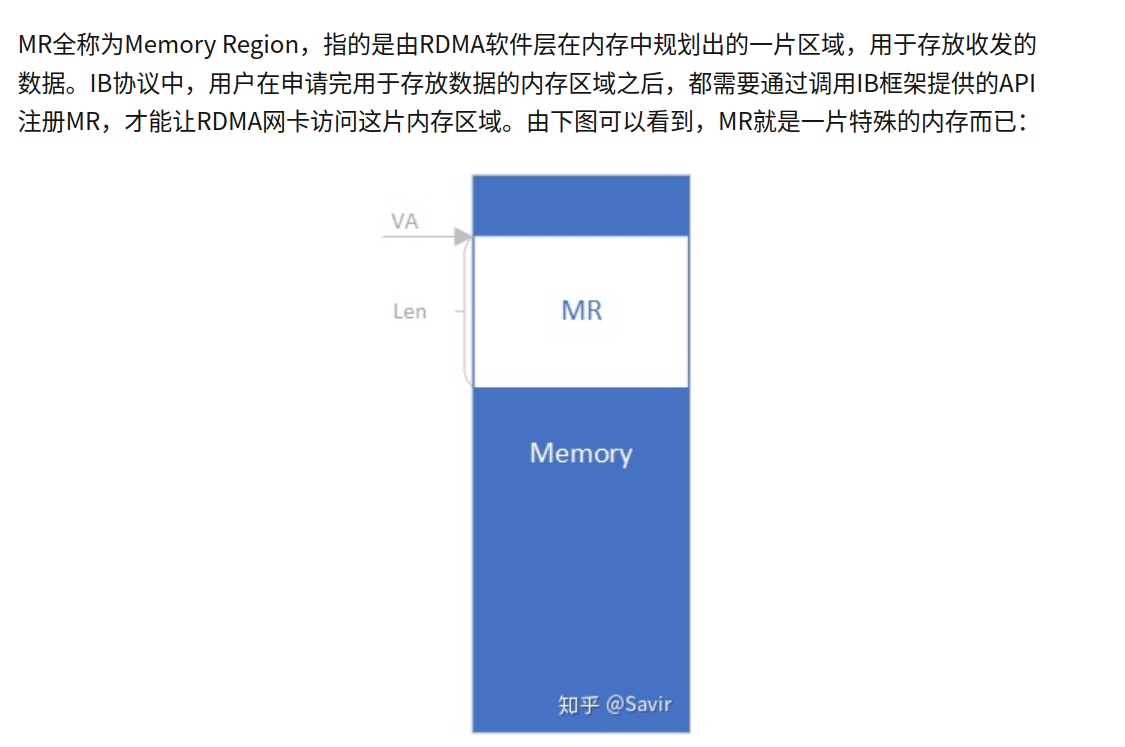
实现虚拟地址与物理地址转换
注册MR的过程中,硬件会在内存中创建并填写一个VA to PA的映射表,这样需要的时候就能通过查表把VA转换成PA了
- 首先本端APP会下发一个WQE给HCA,告知HCA,用于存放待发送数据的本地Buffer的虚拟地址,以及即将写入的对端数据Buffer的虚拟地址。
- 本端HCA查询VA->PA映射表,得知待发数据的物理地址,然后从内存中拿到数据,组装数据包并发送出去。
- 对端HCA收到了数据包,从中解析出了目的VA。
- 对端HCA通过存储在本地内存中的VA->PA映射表,查到真实的物理地址,核对权限无误后,将数据存放到内存中。
对于远端节点来说,地址转换和写入内存都不需要cpu参与(下发wqe也许需要)
控制HCA访问内存的权限
建链的时候,要知道远端节点的可用va和rkey,是通过先建立链路交换而实现的(cm,socket)
避免换页
由于HCA经常会绕过CPU对用户提供的VA所指向的物理内存区域进行读写,如果因为cpu换页前后的VA-PA映射关系发生改变,前文提到的VA->PA映射表将失去意义,HCA将无法找到正确的物理地址。注册MR时”Pin”住这块内存就好了。
RDMA之Protection Domain
一个节点中可以定义多个保护域,各个PD所容纳的资源彼此隔离,无法一起使用。
每个节点都至少要有一个PD,每个QP都必须属于一个PD,每个MR也必须属于一个PD。
PD是本地概念,仅存在于节点内部,对其他节点是不可见的;而MR是对本端和对端都可见的。
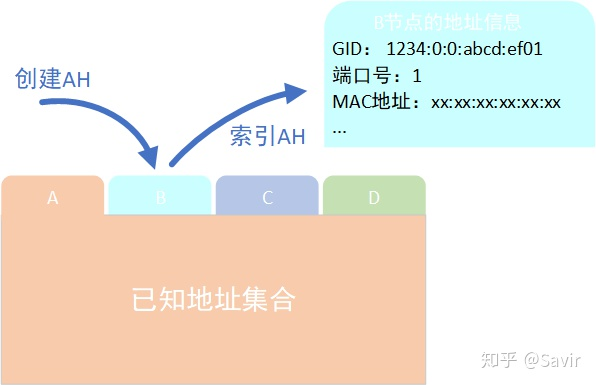
RDMA之Address Handle
qpn是每个qp独立维护的,并不是整个网络唯一的。整个网络唯一的是gid.
RC建链以后,对端信息存在qpc里。ud是在wqe中填写好对端地址。地址指的是gid、端口啥的。
这个对端地址不是直接填,而是通过AH来索引。AH就像一个地址簿
RDMA之queue pair
QPC主要是给硬件看的,也会用来在软硬件之间同步qp信息
qpn为0 1 是特殊的,qp1可以用于cm communication management
控制面来说,qp有增删改查操作,类似ibv_create_qp()的样子
数据面来说,一个qp对上层只有两种接口,用来向qp中填写发送和接受请求。这里的发送不是send,而是一次通信过程的发起放。例如send write read,,,
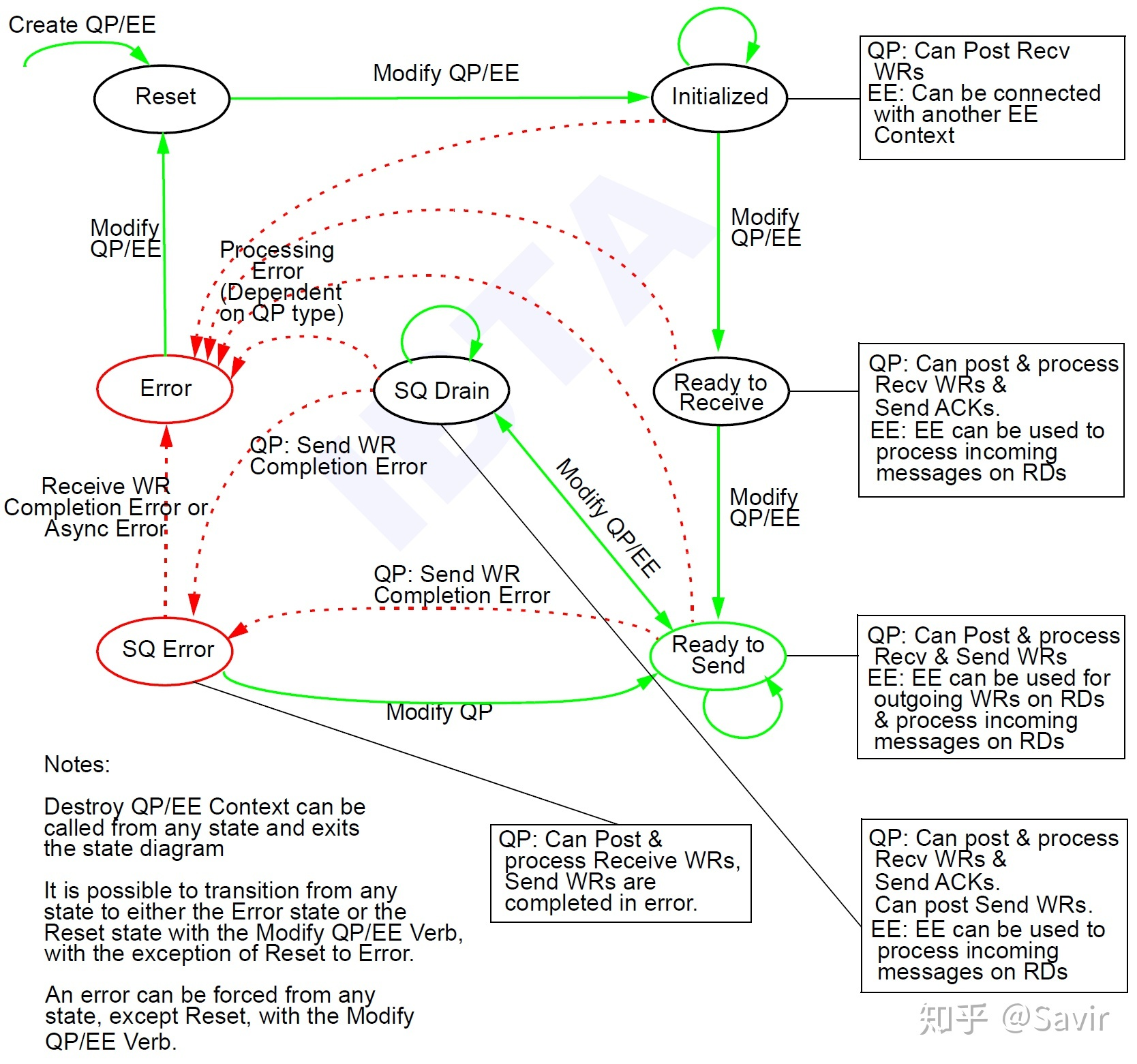
绿色正常态,红色错误态

RDMA之Completion Queue
如果一个WQE对应的CQE没有产生,那么这个WQE就会一直被认为还未处理完
同一个WQ中的WQE,其对应的CQE间是保序的
在RDMA协议中,CQE就相当于是网卡收到的数据包,RDMA硬件把它传递给CPU去处理。RDMA框架定义了两种对上层的接口,分别是poll和notify,对应着传统网卡轮询和中断模式。
RDMA之Shared Receive Queue
通常来说sq任务数量远大于rq(write不需要rqe)
RDMA之memory window
每个MW都会绑定(称为bind)在一个已经注册的MR上,但是它相比于MR可以提供更灵活的权限控制。MW可以粗略理解为是MR的子集,一个MR上可以划分出很多MW,每个MW都可以设置自己的权限。
rdma-tutorial 阅读
https://github.com/jcxue/RDMA-Tutorial/wiki
先看example1,主要就是看代码,不需要写东西。试着编译一下
在实验室s33服务器checkout到对应提交,然后make,提示两个错误
- atoi,要用stdlib.h
- 找不到ibv_xxx函数,链接命令要 -libverbs
在试图跑example1的时候,会出现create_qp参数错误的报错。不好debug。翻一下pr issue,https://github.com/jcxue/RDMA-Tutorial/pull/10 这个pr里面fix了一些RoCE的issue,我记得我们实验室刚好是roce,,,
把他clone下来,使用-w -Wno-address-of-packed-membe屏蔽掉一些报错,就可以运行了。
里面有一些参数,dev_index是ibv_devinfo命令列出的设备索引,服务器有两台,server/client我填了0/1
gid_index 是 ibv_devinfo -v -d mlx5_XXX显示出的索引,我看到了4个,所以都填了3,这个随缘吧
测试命令:
1 | /rdma-tutorial 64 8 7283 0 3 & |
上面的是服务端:message大小64,8个消息并发,监听7283端口,dev_index=0,gid_index=3,&为后台运行
下面的是客户端。测试是把他们放在一台服务器跑了,实际可能可以放好几台分开跑吧
如果看不到输出,像是卡在那里,两个log都不动,也不怕。打开debug模式,可以看到一直在发包,不过要发1000000个才结束,还是要很久的。
我觉得没有太大的必要跑前面的example,重点在阅读代码
ib_write_bw
测试rdma写贷款bandwidth