代码在 https://github.com/poorpool/tinykv ,96.1分。

因为我电脑的 tmpfs 不够大,我在 kv/test_raftstore/cluster.go:61 中把测试目录设置在 /home/poorpool/tinykvtmp 了,提交的时候我把它给删了。如果要想在个人笔记本上跑,可能要这么设置一下,PingCAP 评测的时候应该不需要。
1 2a 2b 2c 3a 3c 4a 4b 4c 一定可以一次跑通,3b 有15%的概率会 fail 一个点,85%的概率一次跑通
日程表
说明:我以前做过一遍 TinyKV,对 Raft 和 Percolator 也有一定的了解。这次是为了拿 TinyKV 抵学校的系统能力综合培养,所以重做了一遍,整洁了代码,整洁了逻辑。
下面的时间是我这一次的耗时,如果算上我以前做第一次的时间,总耗时大概在 25 个整天。
20220702 下载项目,完成 1
20220703 完成 2aa,2ab,但是后面一直在实习,没时间写,忘差不多了
20220808 因为以前写的太糟糕,把代码删了重写,完成了 2aa
20220809 完成了 2ab、2ac
20220810-11 重构代码,加注释,补充 2a 笔记
20220812 阅读 2b 文档,完成代码,能通过 2b 一半的测试
20220813 能通过另一半的测试,完善 2b 笔记,优化 2b 代码;开始写 2c
20220814 完成 2c,完成 3a,完成 3b(留下了一些 bug)
20220815 调 3b bug,进行批量测试,虽然不能 100% 跑过,但是差不多了。休息
20220816 完善 2c 3a 3b 文档,完成 3c
20220817 完善 3c 4a 4b 4c 文档
project 1
要支持四个基本的操作 Put/Delete/Get/Scan,键是key+column。
程序入口在 kv/main.go,会根据是否 raft 来决定使用 raft_storage 还是 standalone_storage(本节内容),最终提供一个 grpc 服务,定义在 proto/proto/tinykvpb.proto proto/proto/kvrpcpb.proto 中。
需要实现的文件在 kv/storage/standalone_storage/standalone_storage.go
要实现的接口
1 | type Storage interface { |
实现的结构体
1 | type StandAloneReader struct { |
在内部维护一个 badger db,使用 engine_util 中的 CreateDB。写的时候将 []storage.Modify 转换为 engine_util.WriteBatch,读的时候获取 badger 事务调用 engine_util 中的函数即可。注意读要求一致性所以要开事务,最后记得 Discard
project 2
project 2a
因为一年半以前写过一次 TinyKv,所以这次把 raft 论文复习了一遍直接就开始写了。写之前看一下网上对 etcd raft 实现的分析,可以学到很多思路。
project 2aa、2ab
日志
首先最好具备优雅地打印日志的能力,比如用一个开关控制自己的日志是否打印。我在 log/log.go 中写了一个 DInfo 函数,由 debugSwitch 控制调试输出,并且因为打印到文件里头,可选地关掉了日志高亮。最好是一开始就能打好日志,后面调试才方便。
连起来看
2aa 实现了领导人选举,2ab 实现了日志复制,但是它们的边界其实没有特别清楚,比如说领导人选举的时候,要确保自己的日志是比较新的,所以两部分会有一点重合。如果按照测试写过去,容易出现 2ab 过了但是 2aa 挂了的问题。因此两个最好连起来看。
我记得我就是完成了 2ab 以后发现 TestLeaderCycle2aa过不了,打印日志,发现测试里有三个人轮流选举当 leader 的过程,1 可以获得 1 2 3 的支持,2 可以获得 2 3 的支持,3 只能得到自己的支持。原因是 3 的日志不够新,追溯日志,是我本来在 becomeLeader 里头添加 no-op 日志条目却没有把他们 append 出去,导致日志不是最新的。
创建
在创建 RaftLog、Raft 的时候,要注意恢复 hardState,正确地处理好各个值的初始化问题。我印象比较深刻的有:
- 从 HardState 中恢复 term vote commit
- 创建的时候不要调用 becomeFollower 把 vote 信息给覆盖了,,,
- 不要漏了 config 中的 applied,感觉是后面才会用到,这里容易忽略掉
- commit stabled 这些都是 index,不是数组下标
重构奥义
我记得我第一次写 TinyKV 的时候,raft.go 一个文件一千多行,函数乱飞,翻起来都不好翻,日志也不好打。这次我吸取上一次的教训,立志精进代码风格:
- 把 raft.go 拆了
- raft.go 处理创建、状态转换、消息分发给处理函数
- raft_sender.go 发消息,每个 MessageType 写一个函数,最终统一调用 send() 来发消息,这样能够统一打日志(非常关键)
- raft_handler.go 用来处理收到的信息
- 函数摆好顺序,按照 MessageType 排序,工具函数放在调用函数的前头一眼就能看见
- 注释!注释!注释!
- 不要追求速度,写完以后重构代码,细化不合理的地方,完善文档。不要像拖拉机一样坑吭吭吭就往下写
下面主要写一下遇到的问题和思考。raft 流程网上已经很充分了。
对 append no-op entry 的思考
raft 要求 leader 不能提交之前任期的日志条目,或者说,提交的日志条目必须包含自己的任期,再说得清楚一些,提交的日志条目必须包含当前最新的任期(raft 论文有很好的例子)。为了在本任期没有收到同步请求的情况下也要能提交之前的日志,应当在成为 leader 的时候立刻 propose 一个空条目并 append 下去。
对收到其他任期的消息的思考
过期消息直接丢弃即可(但是返回一个 response 提示它过期了会不会更好一些)
对于来自大任期的消息,不能简单地接受领导,只有他明确说明自己是领导,才接受。我以前想出来一个很好的例子:1 2 | 3 隔离,1 term 6 leader, 3 term 7 candidate 。解除隔离以后,1 收到了 3 的请求投票 rpc,要更新自己的任期,但是不能接受对方的领导。只有明确声明自己是领导才承认,即 Append 和 Heartbeat
其他小问题
- leader 收到同任期 candidate 投票请求也要投拒绝票,而不是 drop message
- append 日志的时候有很多细节要想清楚,例如 leader.commit > my.commit 时, commit = min(leader.commit, leader 给我的 lastIndex(不是我的最后一个 lastIndex)),因为你返回的 match 不可以比 leader 现在 lastIndex 还大
- 收到心跳要发回复,收到心跳回复要检查 progress 并确定要不要发 append
- commit 增加了,才广播 append
project 2ac
稍微简单一些,实现 raft 的上层节点 RawNode,返回 Ready,代表上次处理完 Ready 以后和这次的更改。为此要保存下来之前的 SoftState 和 HardState。在返回新 Ready 时,如果 SoftState 和以前的不一样,才返回有值的 SoftState,否则返回空。
出 Ready 时,还会清空消息。Advance 更新 RawNode 的各种 State,处理日志 stabled applied
project 2b
从 2b 开始,文档、测试和实现之间的 gap 就有点大了。有两个文档很推荐看,不要闭门造车,要见贤思齐(不是抄袭)
这一章最终要体现在 kv/raftstore/peer_storage.go kv/raftstore/peer_msg_handler.go,代码是在这两个文件里头写的。并且很有可能返工修改 2a。
结构体关系
首先了解一下这些结构体的相互关系:
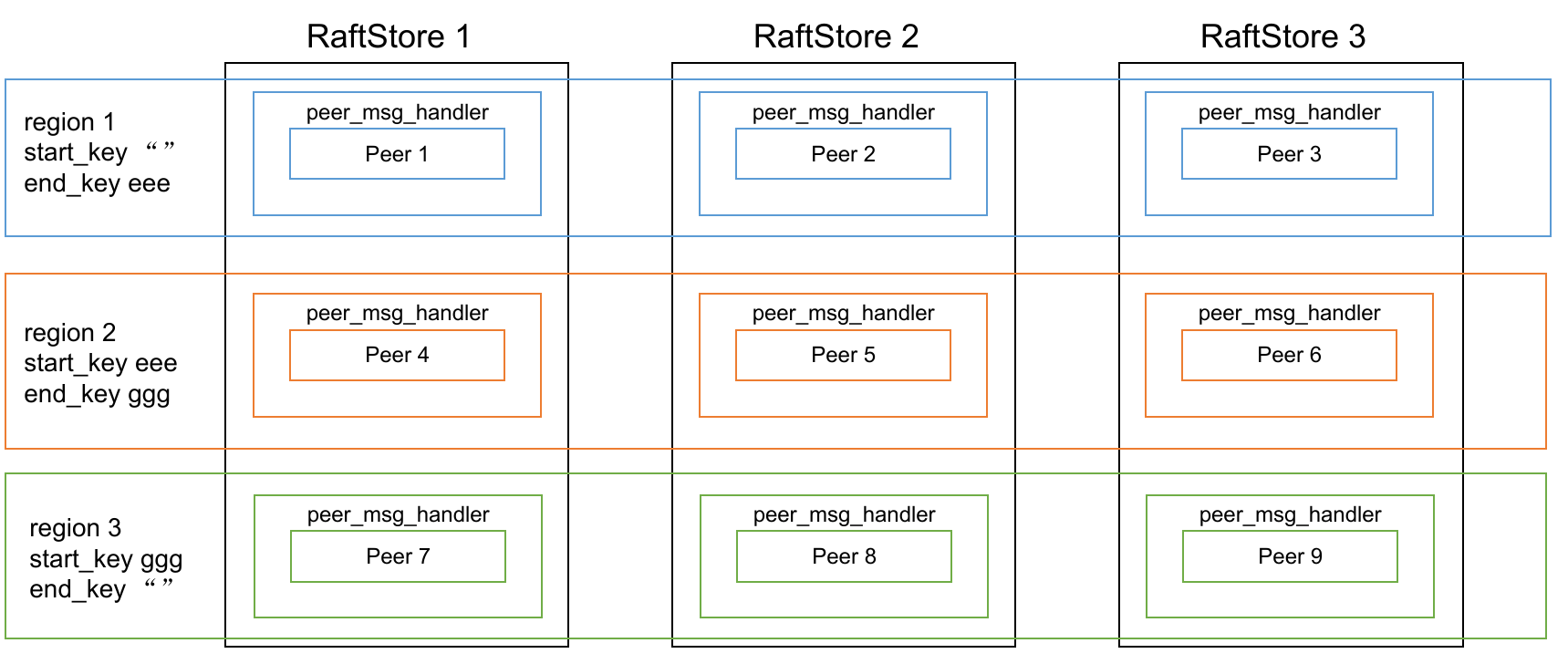
上面这一串,整体是作为 RaftStorage,RaftStorage 实现了我们在实验一里头实现的接口:
1 | type Storage interface { |
它收到请求以后,会一通分发,进入 peer_msg_handler 处理消息。
1 | type peerMsgHandler struct { |
peerMsgHandler 基于 peer:
1 | type proposal struct { |
注意这里头还有一个 metapb.Peer,存放了 peer id 和 store id。
1 | package metapb; |
回到刚才说的 peer,它有一个 RaftGroup,意味着它就是 raft 中的一个节点。这个节点的 Storage,就是 PeerStorage:
1 | type PeerStorage struct { |
1 | message HardState { |
PeerStorage 实现了我们在 Raft 中的 Storage 接口:
1 | type Storage interface { |
peer_msg_handler 的 proposeRaftCommand()
注意:这里和后面的代码都是经过摘取的,真实的代码中肯定还包含了错误校验等一系列其他繁琐的事情。
上面提到了,读写请求最后都会到达 proposeRaftCommand,在这个函数中把读写请求序列化作为一条日志条目 propose 进 Raft,让它去 append、commit、apply。我们要等日志 apply 的时候才能返回给客户端 response。考虑到 apply 的时候也是在这个 peer_msg_handler 里面,我们给他维护一个 proposal 结构,能够得到日志条目和回调的对应关系。
也就是说,我们在这个函数里干的事情主要是(省略了错误处理)
1 | data, err := msg.Marshal() |
代码都比较好理解。appendProposal 是我自己写的记录回调的函数,理论上来说应该使用日志条目 index 和 term,但是在 raft 之外的上层无法取得,我们直接取最后一条日志后面的 index 就好:
1 | func (p *peer) nextProposalIndex() uint64 { |
增加回调是一个麻烦的事情,因为我们都知道并不是 propose 了的日志条目就会被 commit 被 apply,有可能被覆盖掉。我们希望 proposal 数组里头也要像日志数组里头一样干干净净,index 递增,就要在增加 proposal 的时候删除冲突的日志条目,也就是 index 大于等于当前 proposal.index 的条目都删除掉。 当然,这里不能直接删除,要把要被删除的回调都返回一个 ErrRespStaleCommand,可以理解为要求客户端重试的统一回复。
1 | func (d *peerMsgHandler) appendProposal(index uint64, term uint64, cb *message.Callback) { |
peer_msg_handler 的 HandleRaftReady()
Raft 消息的最终宿命是被丢掉或者被 apply,apply 等一系列变化会体现在 Ready 中,处理的函数就是 HandleRaftReady(),它的流程大概如下:
1 | func (d *peerMsgHandler) HandleRaftReady() { |
它首先调用 peer_storage 的 SaveReadyState() 保存 raft 日志、HardState 等状态,然后把消息发送出去
hint:使用 GlobalContext 中的 Transport 来发送 Raft消息
接下来轮番应用日志,并且及时更新 ApplyState(后面停机了删除 ApplyState 的代码我忘了是哪一部分引入的了,也贴上来)
hint: 应用每一条日志都要赶快更新、持久化 ApplyState,不然会造成数据不一致
hint: 使用 WriteBatch 来确保写入一致性,例如,使用一个 kvWb 来同时保存 key-value 更新和 applyState 的更新
应用普通日志的代码:
hint: 找不到回调也要 apply
1 | func (d *peerMsgHandler) applyNormalRequest(msg *raft_cmdpb.RaftCmdRequest, |
hint: snap 请求回调应该设置事务 Transaction 为 false
应用普通日志的时候,要查找回调,即顺着 proposal 数组查找到自己要的 index,并且删除没有用的回调。一定要记住,日志的匹配要求 index 和 term 都匹配:
1 | func (d *peerMsgHandler) findProposal(index uint64, term uint64) *proposal { |
peer_storage SaveReadyState()
1 | func (ps *PeerStorage) SaveReadyState(ready *raft.Ready) (*ApplySnapResult, error) { |
这里省略了对 snapshot 的处理,这是 2c 的部分了。我们回顾一下 Ready 的结构:
1 | type SoftState struct { |
Message、CommittedEntries 不是要保存的内容,因此只有 HardState Entries 需要保存。
peer_storage Append()
Append 函数保存日志。
回忆一下这个表格:
| Key | KeyFormat | Value | DB |
|---|---|---|---|
| raft_log_key | 0x01 0x02 region_id 0x01 log_idx | Entry | raft |
| raft_state_key | 0x01 0x02 region_id 0x02 | RaftLocalState | raft |
| apply_state_key | 0x01 0x02 region_id 0x03 | RaftApplyState | kv |
| region_state_key | 0x01 0x03 region_id 0x01 | RegionLocalState | kv |
日志条目和 RaftLocalState 状态都存在 raftDB 里面,和上面的kvDB一样,都是一个单机数据库。
根据提示,保存日志要分三步走:
1 | func (ps *PeerStorage) Append(entries []eraftpb.Entry, raftWB *engine_util.WriteBatch) error { |
这里有一个 peer_storage_test.go 测试文件,可以用来辅助测一下 append 函数。
firstIndex 不从 0 开始
打印了日志以后发现,firstIndex 从 5 开始,其实文档里面有说 Note that the value of both RAFT_INIT_LOG_TERM and RAFT_INIT_LOG_INDEX is 5。这样的话,我原本 RaftLog 里面没有日志的时候 lastIndex 返回的是 0,现在看来应该返回的是 firstIndex - 1。对应的 Term 也要从 storage 里头取了。
做到这里还返回去改造了 Raft 和 RaftLog,感觉以后还要接着改造,,
peers 错误
做 2b 的时候打日志调试,意外地发现遇到了所有人都是 leader 的诡异情况。打印构造情况,发现 c.peers 只有自己一个人,要从 confState 里面取。暂时还不清楚这个是干啥的,但是取了就可以了。
莫名其妙的 fail
第一次做 tinykv 的时候遇到过这种情况,tmpfs 是基于内存的,我的内存 16g 扛不住,kv/test_raftstore/cluster.go:61 里面把临时文件夹放在 ssd 里面,现在可以跑过了,但是要自己清空测试文件夹。
getWrongValue 以及 CmdType 错误
也是打日志一通观察,发现这样的一个场景:
1 2 3 4 5,起初 2 为 term 6 leader,后来 1 2 | 3 4 5,4 为 term 7 leader。2 propose 了日志 a,4 propose 了日志 b,不幸地它们 index 相同
,4 的日志会覆盖 2 的,因此 2 apply 的时候也要检查 term,看记录 proposal 的时候和现在的日志的 term 是否一样。如果不检查 term,2 会 apply 4 的日志条目 b,但是回调 a,造成错误。
给 proposal 比对的时候加上 term,如果 term 和当前 term 不一样,就返回 StaleCommand。
从崩溃中恢复
在可能崩溃的测试中,出现了这样的问题:unexpected raft log index: lastIndex 5 < appliedIndex 3359
一看就是持久化没做好,观察 panic 的地方,是 RaftLocalState 没有保存。一通断点调试,发现 RaftLocalState 我保存之前的时候是存的指针,修改的时候,指针指向的地方值会变,就没有保存好以前的 RaftLocalState。没想到给指针搞了,,,
测试的时候自己写一个 shell 脚本,连续跑测试很多次,会很有助于调试。因为 2b 开始不是跑一遍就能测出来的了。
project 2c
完成快照。比方说现在 1 2 3 4 5,5 号挂了很长时间,其他四个人都 apply 很多日志了,这时候 5 恢复,没有必要给他发送那么长的日志,直接给他发一条快照就好了。
实现快照需要稍微改造一下 raft 模块,然后在 2b 的基础上增加一些改动。
RaftLog 的改动
我们引入一下 snapshotIndex snapshotTerm 的概念。2a 的 firstIndex 是第一条日志条目的 index,那 snapshotIndex 就是被归档不可用的最后一条日志条目的 index,初始化为 firstIndex - 1,对应的 Term 从 storage 中取得。
RaftLog 里面有一个 pendingSnapshot,名字顾名思义。因为它的存在,lastIndex() 什么的也要修改。比如一个新创建的 peer 被发送了 snapshot,我们就说这个 lastIndex 就是 pendingSnapshot 的 lastIndex,不能说是 0。
1 | func (l *RaftLog) LastIndex() uint64 { |
应用快照的时候,除了要设置各种 index,还要把现有的日志条目清空。因为应用快照就代表着完全接受快照:
1 | func (l *RaftLog) applySnapshot(snap *pb.Snapshot) { |
这里的 applySnapshot 名字其实起得不好,它不是发生在 apply 阶段的,而是 handleSnapshot 时候被调用的,就像 handleAppend 一样。
raft 模块
需要明确一下,snapshot 的地位和 append heartbeat 的地位是一样的,都是 leader 宣示自己的领导地位,因此处理 snapshot 的时候也要和 append 一样处理任期和 state。
下面的代码比较清楚了,如果取得不到日志条目,就发送快照。因为取得快照是一个耗费时间的任务,可能暂时不可用,这样的话就跳过发送。
1 | func (r *Raft) sendAppend(to uint64) bool { |
处理快照的时候要注意,忽略 commit 不能增加的快照,这个会被认为是过期的,但是也要返回给 leader 提示,让他以为是成功更新,不然 leader 一直收不到回复,就会一直发快照而卡死。不要忘记处理 Prs。
1 | func (r *Raft) handleSnapshot(m pb.Message) { |
peer_storage
RaftLog 接收到 Snapshot 以后,会体现在 Ready 中,目的是更新一下各种 State,在 SaveReadyState 中自然也要添加上这一点。
1 | func (ps *PeerStorage) SaveReadyState(ready *raft.Ready) (*ApplySnapResult, error) { |
ApplySnapshot() 比较复杂,但是步骤也很清晰:
- 删除旧信息。快照的应用让 Raft 日志条目等信息变得无用。不过,删除的时候要注意 ps.isInitialized() 才可以删除,不然会产生错误
- 更新 raftState、applyState、regionState。这是因为快照也可能包含新的 region 的信息
- send
runner.RegionTaskApplytask to region worker throughPeerStorage.regionSchedand wait until region worker finishes.
1 | func (ps *PeerStorage) ApplySnapshot(snapshot *eraftpb.Snapshot, kvWB *engine_util.WriteBatch, raftWB *engine_util.WriteBatch) (*ApplySnapResult, error) { |
peer_msg_handler
快照消息的产生、发送、处理是在 raft 模块中的。在上层 peer_msg_handler,我们实际上处理的是压缩日志请求。不同于增删改查,这是一个 adminRequest,因此也要相应在 propose 的时候做出一些调整。
首先,AdminRequest 不会和普通 Request 一起出现;压缩日志请求没有回调,所以不需要处理 proposal 相关的逻辑。
同样地,在处理 Ready 的时候,我们也要处理一下 AdminRequest 了。对应的处理逻辑文档里写得很清楚了,这里粘贴一下:
1 | func (d *peerMsgHandler) applyAdminRequest(msg *raft_cmdpb.RaftCmdRequest, |
根据我的理解,ScheduleCompactLog 最终会导致 Storage 中的日志被压缩掉。因此要时不时压缩一下我们在内存中的 RaftLog 保存的日志,也就是 maybeCompact 函数(自己在 Rawnode 中调用它)
1 | func (l *RaftLog) maybeCompact() { |
如果 storage 里头不存日志条目了,那内存中也不存了。
project 3
project 3a
实现领导人禅让(又叫转换),增加节点,删除节点。不难,但是可能会给 3b 埋坑,,,
领导人禅让
领导人禅让基本上也可以称为 local message,因为它不会被传播。把这条消息往下 step 的时候要注意: 如果自己不是 leader,就把消息转发给 leader
我们使用 leadTransferee == 谁 来标记当前在试图禅让给谁,禅让的判定过程叫 handleTransferLeader(to uint64),
- to 被删了、to 是自己,返回
- 更新领导人禅让计时器,记录 leadTransferee
- 检查 leadTransferee 日志情况。如果和自己日志一样新,就向他发送 MsgTimeoutNow,leadTransferee 收到以后会和收到 MsgHup 一样立刻开始选举
- 如果 leadTransferee 日志没自己新,就给他发 append
与此同时,handleAppendResponse 里面,如果接收到来自 leadTransferee 的消息,就重新调用 handleTransferLeader 检查禅让情况
需要注意的事情:
- 在领导人转换期间,禁止一切 propose。直接返回 ErrProposalDropped
- 如果 leadTransferee 挂了,就会导致领导人禅让计时器超时,这种情况下终止禅让,不然一直不能 propose
增删节点
增加节点,就要更新 Prs,设置好它的 Match 和 Next(lastIndex + 1)。如果是 leader,可以考虑立刻广播心跳,因为 peer 的创建是根据消息的 to 不存在而创建的,这样可以尽快达成一致
删除节点,也要更新 Prs,也要尝试更新 commit 和广播 append
project 3b
如果说《春江花月夜》是诗中的诗,顶峰上的顶峰,那 3b 一定是 TinyKV 中的顶峰了,不论是它的抽象程度还是困难程度,还是找不到 bug 在哪里的痛苦,以及测试的耗时,,,做这一部分的时候要多参考参考其他人的文档,跟同学讨论讨论,上网搜索报错和 bug,时刻保持心态的平和。
3b 分为三部分,第一部分实现领导人转换,很简单不需要很多功夫,收到这个 adminRequest 的时候直接调用 RawNode 的相关方法然后返回就行,不需要 propose;第二部分实现配置变更;第三部分实现 multi-raft 的 region split
我跑了 28 次,有 4 次会 fail,每次 fail 一个点。
配置变更
配置变更也是作为 AdminRequest 来到 proposeRaftCommand 的,但是因为它比较特殊,不仅要通过 Raft 同步,还要修改 Prs,为了表示区分,它在日志条目中的 Type 为 EntryType_EntryConfChange,并且有一个专门的 ProposeConfChange(cc pb.ConfChange) 方法,因此,proposeRaftCommand 处理这个 AdminRequest 也稍微有一点变化:
1 | context, err := msg.Marshal() |
把 msg 也传进去,因为后面可能要捞出来检查版本。
因为我们一次只处理一个节点变更,日志条目容不得两个节点变更的未 apply 日志存在,所以要用 pendingConfIndex 确保只有一个节点变更日志等待 apply
此后同样的步骤,我们首先把内容都取出来,检查 Region 版本是否匹配。如果不匹配,说明已经过时了。
1 | confChange := &pb.ConfChange{} |
接下来,如果是增加节点,我们就
- 更新 region ConfVer
- 插入到 peer Cache 中
- 插入到 peer 数组中
- 写入 WriteBatch
1 | d.Region().RegionEpoch.ConfVer++ |
如果是删除节点,则要分类讨论:删除自己就 destroyPeer(),删除别人使用和上面差不多的技法。
region split
split adminRequest 的地位和压缩日志一样,因此直到 apply 前,处理的方法都大差不差。
注意:引入 split 以后,get put delete 要检查 key 是否在 region 中。 split apply 的时候也要检查 key 是否在 region 中、版本对不对,步骤大概为:
- 创建新 region
- 修改当前 region 的 Version,endKey,storeMeta(记得加锁)等等
- 使用 ReplaceOrInsert 更新 regionRanges,也写入 WriteBatch
- 在当前 store 创建 peer
- 向路由注册 peer
- 向新 region 发送 start
- 回调
meta corruption detected 问题
我参考的 https://github.com/LX-676655103/Tinykv-2021/blob/course/doc/project3.md,这个问题的出现是在 destroyPeer 中,meta.regionRanges.Delete(®ionItem{region: d.Region()}) == nil 导致的。删除为空,是因为新创建的 peer 没有插入到 regionRanges 中。因此要在 maybeCreatePeer() 最后面加一句 meta.regionRanges.ReplaceOrInsert(®ionItem{region: peer.Region()}),这样就不会出现无效删除的问题了。
增删节点导致的 request timeout
我搜索到了这个问题 https://asktug.com/t/topic/274196/1,观察日志还真是这样。比方说最后剩下 1 2,1 是 leader 要删除自己,1 send append to 2, 2 send appendResponse to 1, 1 update commit and destroy itself。考虑到 commit 更新了,1 要发给 2 commit 更新的消息,但是如果这条消息不幸被 drop 掉,2 就不知道 1 给删除了!!!此时,2 一直不知道 1 给删除了,试图发起投票,当然是无尽的失败。
我也用的邪道,在 handleAppendResponse 里面,如果要更新 commit 广播 append,就把 append 连续广播五遍,减少消息丢失的可能性,,,但是这样挺不优雅的
proposal 导致的 request timeout
原来我对 proposal 处理得比较粗浅,打印出来发现它不是单调的,使用了 append rpc 类似的方法来确保它单调。但是还是有很小的概率不单调,可能是并发操作吧。
storeMeta 导致的 request timeout
我发现在增删节点的时候加锁修改 storeMeta 容易增加超时几率,很迷惑,暂时不太会改,只能在这里不修改它了。
参考了,不过没有用 https://asktug.com/t/topic/274160
no region 问题
参考了 https://github.com/Smith-Cruise/TinyKV-White-Paper/blob/main/Project3-MultiRaftKV.md 增加了一个方法,快速刷新 scheduler 的缓存,有效避免了 no region 问题。
project 3c
完善调度器。这是一个独立的部分,可以喘一口气了,但是也要多跑几遍。
第一个要求是实现对 region 心跳的处理,在 scheduler/server/cluster.go 中的 processHeartBeat()。
首先写一个比较 region 谁更新的函数,先比较 Version 再比较 ConfVer
1 | func regionANewerThanB(a *metapb.Region, b *metapb.Region) bool { |
注意这里要使用 Get 方法,因为可能有 nil,,,
然后检查心跳是否可以接受,首先检查同 id 的 region 谁更新,然后检查和 heartbeart region 重叠的 region,新 region 要都比他们新。
1 | if reg, _ := c.GetRegionByID(region.GetID()); reg != nil && regionANewerThanB(reg, region.GetMeta()) { |
然后就可以调用 PutRegion() 和 updateStoreStatusLocked()(这个函数更简单)来更新 region 情况了。
第二部分是选择一个 store,将 region 从这个 store 迁移到另一个 store。在 scheduler/server/schedulers/balance_region.go
- 取出所有 IsUp() 并且 DownTime 合格的 store,把他们按照 regionSize 从大到小排序
- 依次考察 store,对于每个 store
- 试图选择一个 pendingRegion
- 选不到就试图选择一个 followerRegion
- 选不到就试图选择一个 leaderRegion
- 还选不到就考察下一个 store
- 现在我们得到了要迁移的 region 和它的 store
- 检查 region 的 store 数量,没有超过 cluster.GetMaxReplicas() 的话,就返回。因为他可以直接创建一个 peer,而不是迁移
- 取得一个目标 store,要求 regionSize 尽量小,且不在 region 原来的 store 中
- 要求 store size 差比较大,这样迁移才有意义,也就是要
region.GetApproximateSize() < 2*(fromStore.GetRegionSize()-toStore.GetRegionSize()) - AllocPeer, CreateMovePeerOperator
project 4
4a
实现一个 MvccTxn,辅助后面的实现。
column family 派上用场。
- CFLock 对应 Lock,写 key 没有 timestamp,在 value(lock 结构体)里面保存 Lock 的 startTs
- CFDefault 对应 value,写 key 包含 startTs
- CFWrite 对应 Write,写 key 包含 commitTs,在 value(write 结构体)里面保存 Write 的 startTs
PutWrite GetLock PutLock DeleteLock DeleteValue 都比较直观(注意没有 DeleteWrite)
Write 的 Get 方法有两个,CurrentWrite 从 EncodeKey(key, TsMax) 开始遍历,遍历趋势是同 key 的 commitTs 变小,然后到不同 key。把 startTs 取出来,startTs 要和 txn.StartTs 相同,才是当前事务的 Write;MostRecentWrite 也是要 seek 一下,能找到同 key 的就返回了。
GetValue 要取得在 txn.StartTs 这一刻有效的 Value,因此从 EncodeKey(key, TsMax) 找最新 Write,如果 WriteKind 为 Delete 就返回 nil,否则就取出这个 Write 的 startTs 在 CFDefault 中的值(其实我有点疑惑这里不用考虑 WriteKind 为 rollback 吗)
project 4b 4c
在 kv/server/server.go 中实现 KvGet KvPreWrite KvCommit,使用上面的 MvccTxn。
Percolator 事务基本形状:
- Prewrite。对于每一个 key,检查错误,有的话返回所有错误,没有的话 apply txn.Writes()
- 检查 MostRecentWrite,有没有 commitTs >= txn.StartTs 的 write 的?有的话记录 Write 冲突
- 检查 Lock,有不是自己的 lock(lock StartTs 对不上),记录已经被锁
- 现在这个 key 没有问题了
- 给这个 key 加上锁
- 写入 value 到 CFDefault 中(写入 Value 发生在 PreWrite 阶段!!)
- CheckTxnStatus,以 primary key 为准
- 检查 lock 情况,如果没 lock 或者不是自己的 lock,就检查 CurrentWrite
- write != nil,那说明事务已经执行。通过 write 的 Kind 来设置 resp 的 commitVersion
- write == nil,事务不行了,向 Write 中写入 WriteKind_ROLLBACK(这里不用删除 Value,删除 value 是在 rollback)
- 自己的 Lock 还在,但是 lock 超时了,就向 Write 中写入 WriteKind_ROLLBACK,删 lock,删 Value
- 事务没问题,返回
- 检查 lock 情况,如果没 lock 或者不是自己的 lock,就检查 CurrentWrite
- Commit 首先使用 Latch 对 keys 统一加锁,然后对于每个 key
- 取 lock,如果没 lock,取得 CurrentWrite,如果已经提交就忽略,其他情况报错
- 不是自己的 lock,返回错误(可以重试)
- 写入 write
- Rollback 也差不多,先统一加锁,然后对于每一个 key
- 取 CurrentWrite,已经回滚就 continue,其他情况就 Abort
- 写入 write
- 如果自己 lock 着,就删除 value 和 lock
- KvResolveLock 就是取得当前 txn.StartTs 的所有 lock,根据 commitVersion 决定是提交还是回滚
- KvGet 的时候可以使用
lock.IsLockedFor(req.Key, txn.StartTS, resp)来检测 lock 冲突,还会自动设置 resp 的 Error 字段,很方便。简单来说就是如果 lock 不是自己的就报错,不然就 GetValue 返回去 - KvScan 也差不多,就是要自己实现 Scanner,确保对于每一个 key 都返回一个 value,下次就是另一个 key